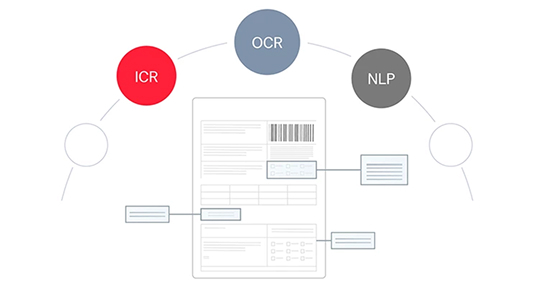
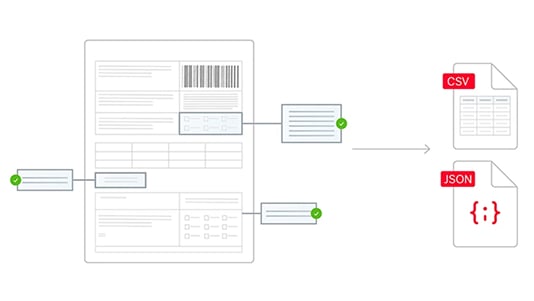
Any document, any language, any complexity
Extract accurate data from structured, semi-structured, and unstructured documents in 200+ languages, including complex multi-page files and tables.
150+ pre-trained extraction models
Deploy ready-to-use AI models that automatically identify and extract key fields and continuously improve with real business documents.
Low-code custom model creation
Create and train custom extraction models in minutes using just a few examples, no coding required.
Auto-labeling for faster model setup
Automatically identify and label key data fields from the first document to accelerate model development and deployment.
90%+ straight-through processing from day one
Achieve high levels of touchless processing immediately, reducing manual work, operational costs, and turnaround time.
Continuous learning built in
Models learn from human feedback and adapt to new document formats, improving accuracy over time.
Advanced handwritten data extraction
Accurately capture handwritten and cursive text from complex documents where legacy ICR struggles.
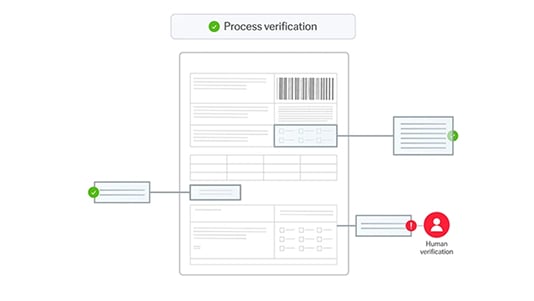
Built-in data validation & normalization
Automatically validate, cross-check, and normalize extracted data to deliver clean, reliable outputs for downstream systems.